
Readability scores were originally developed to assist primary and secondary educators in choosing texts appropriate for particular ages and grade levels. They were then picked up by industry and the military as tools to ensure that technical documentation written in-house was not overly difficult and could be understood by the general public or by soldiers without formal schooling.
There are many readability metrics. Nearly all of them calculate some combination of characters, syllables, words, and sentences; most perform the calculation on an entire text or a section of a text; a few (like the Lexile formula) compare individual texts to scores from a larger corpus of texts to predict a readability level.
The most popular readability formulas are the Flesch and Flesch-Kincaid.
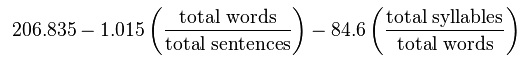
Flesch readability formula
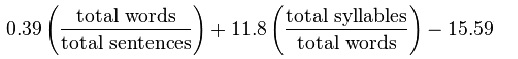
Flesch-Kincaid grade level formula
The Flesch readability formula (last chapter in the link) results in a score corresponding to reading ease/difficulty. Counterintuitively, higher scores correspond to easier texts and lower scores to harder texts. The highest (easiest) possible score tops out around 120, but there is no lower bound to the score. (Wikipedia provides examples of sentences that would result in scores of -100 and -500.)
The Flesch-Kincaid grade level formula was produced for the Navy and results in a grade level score, which can be interpreted also as the number of years of education it would take to understand a text easily. The score has a lower bound in negative territory and no upper bound, though scores in the 13-20 range can be taken to indicate a college or graduate-level “grade.”
So why am I talking about readability scores?
One way to understand”distant reading” within the digital humanities is to say that it is all about adopting mathematical or statistical operations found in the social, natural/physical, or technical sciences and adapting them to the study of culturally relevant texts. E.g., Matthew Jocker’s use of the Fourier transform to control for text length; Ted Underwood’s use of cosine similarity to compare topic models; even topic models themselves, which come out of information retrieval (as do many of the methods used by distant readers); these examples could be multiplied.
Thus, I’m always on the lookout for new formulas and Python codes that might be useful for studying literature and rhetoric.
Readability scores, it turns out, have sometimes been used to study presidential rhetoric—specifically, they have been used as proxies for the “intellectual” quality of a president’s speech-writing. Most notably, Elvin T. Lim’s The Anti-Intellectual Presidency applies the Flesch and Flesch-Kincaid formulas to inaugurals and States of the Union, discovering a marked decrease in the difficulty of these speeches from the 18th to the 21st centuries; he argues that this decrease should be understood as part and parcel of a decreasing intellectualism in the White House more broadly.
Ten seconds of Googling turned up a nice little Python library—Textstat—that offers 6 readability formulas, including Flesch and Flesch-Kincaid.
I applied these two formulas to the 8 spoken/written SotU pairs I’ve discussed in previous posts. I also applied them to all spoken vs. all written States of the Union, copied chronologically into two master files. Here are the results (S = spoken, W = Written):
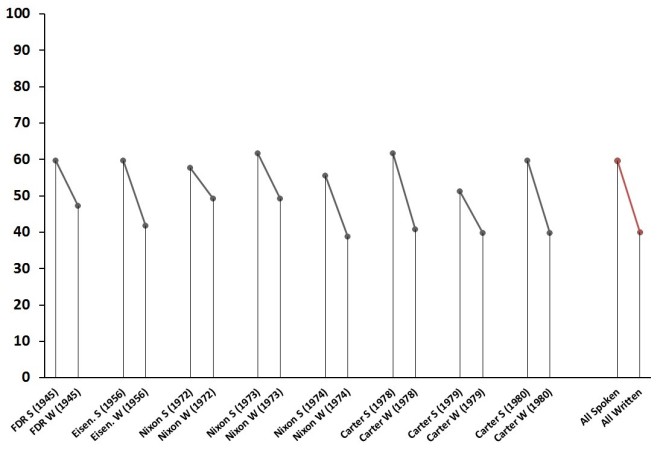
Flesch readability scores for States of the Union. Lower score = more difficult.
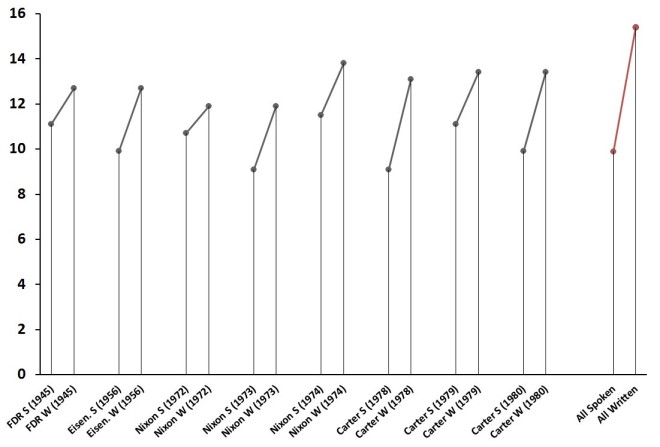
Flesch-Kincaid grade level scores for States of the Union.
The obvious trend uncovered is that written States of the Union are a bit more difficult to read than spoken ones. Contra Rule et al. (2015), this supports the thesis that medium matters when it comes to presidential address. Presidents simplify (or as Lim might say, they “dumb down”) their style when addressing the public directly; they write in a more elevated style when delivering written messages directly to Congress.
For the study of rhetoric, then, readability scores can be useful proxies for textual complexity. It’s certainly a useful proxy for my current project studying presidential rhetoric. I imagine they could be useful to the study of literature, as well, particularly to the study of the literary public and literary economics. Does “reading difficulty” correspond with sales? with popular vs. unknown authors? with canonical vs. non-canonical texts? Which genres are more “difficult” and which ones “easier”?
Of course, like all mathematical formula applied to culture, readability scores have obvious limitations.
For one, they were originally designed to gauge the readability of texts at the primary and secondary levels; even when adapted by the military and industry, they were meant to ensure that a text could be understood by people without college educations or even high school diplomas. Thus, as Begeny et al. (2013) have pointed out, these formulas tend to break down when applied to complex texts. Flesch-Kincaid grade level scores of 6 vs. 10 may be meaningful, but scores of, say, 19 vs. 25 would not be so straightforward to interpret.
Also, like most NLP algorithms, the formulas take as inputs things like characters, syllables, and sentences and are thus very sensitive to the vagaries of natural language and the influence of individual style. Steinbeck and Hemingway aren’t “easy” reads, but because both authors tend to write in short sentences and monosyllabic dialogue, their texts are often given scores indicating that 6th grades could read them, no problem. And authors who use a lot of semi-colons in place of periods may return a more difficult readability score than they deserve, since all of these algorithms equate long sentences with difficult reading. (However, I imagine this issue could be easily dealt with by marking semi-colons as sentence dividers.)
All proxies have problems, but that’s never a reason not to use them. I’d be curious to know if literary scholars have already used readability scores in their studies. They’re relatively new to me, though, so I look forward to finding new uses for them.

Pingback: Dumb Yanks and witty Brits. | Stuff I Done Wrote - The Michael A. Charles Online Presence